[CS:APP 11] The Memory Hierarchy
11화 The Memory Hierarchy
이번에는 하라보지 교수님이 아니라 아조시 교수님이 수업하신다
개인적으로는 이분 영어가 더 잘 들려서 좋다...
Memory Hierarchy를 설명하기 위해 갖가지 storage device들의 스펙들에 대해 설명한다
오늘은 이론적이고 전체적인 부분에 대해 개관한다.
저장장치들 storage devices
내용은 많지만 핵심은
값이 쌀수록 용량이 크고 대신 느리다
비쌀수록 용량은 작고 빠르다
그러하다.
SSD
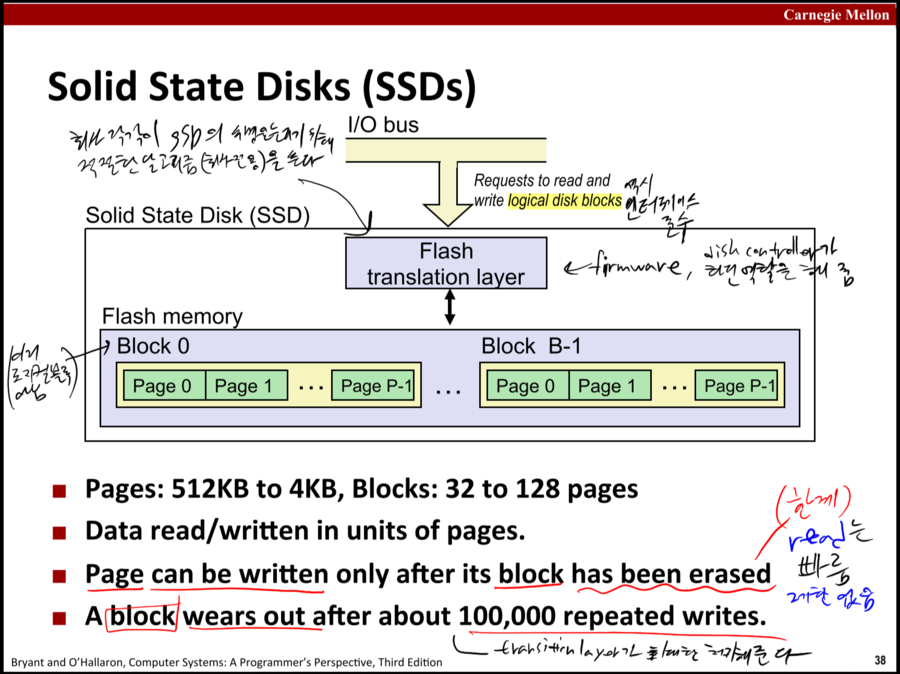
SSD는 위와 같은 구조를 이루며, HDD처럼 쓰기 위해서 logical disk block이란 가상의 개념(원래 HDD가 쓰던 개념)을 따른단다
뭔가.. 가상 메모리 같은 건가 보다(그림의 block은 그거는 아니고 진짜 하드웨어 블록임)
추상화랑 일맥상통하는 부분이 있지만 그런 이야기는 나중에 하자..
그리고 SSD는 그림의 블록 하나를 다 지워야만 page에 데이터를 쓸 수 있다. 왜? 는 설명 안 해줌 뭐 장치가 그렇다는데 그런거겠지..
그래서 쓰는 게 읽는 거보다 느리고(읽는 건 제한 없음) 10000번을 쓰면 못 쓴댄다.
공짜 점심은 끝났다
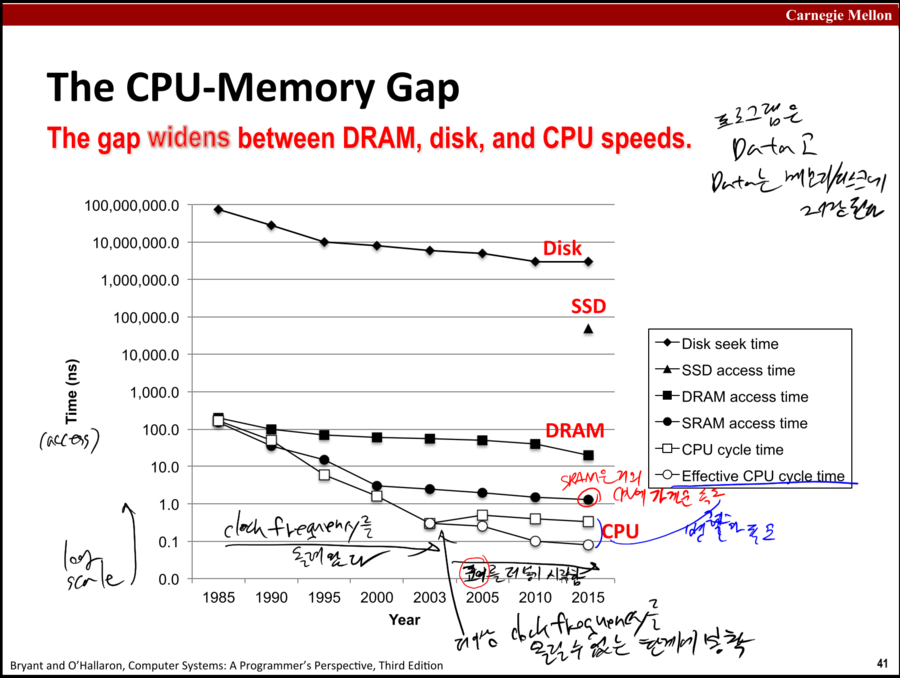
1985에서 2003년까지는 2년마다 2배씩 꾸준히 성능이 증가한다. 그런데 2003년에는 그 한계를 맞는다.
더이상 clock frequency를 증가시킬 수 없게 된 것이다. 공짜 점심은 끝났다...
이 때부터 CPU 제조사들은 코어를 늘릴 생각을 하게 된다
그래서.. 병렬 프로그래밍이 중요해진 것이고
CPU cycle time과 Effective CPU cycle time이 차이 나는 이유가 바로 병렬 프로그래밍 때문인 것이다.
그런데 그 병렬 프로그래밍을 가장 하기 쉬운 패러다임이 바로 함슬람이다.
람다후 함크바르!
Clojure가 미래의 언어라는 과격한 주장이 나오는 이유도 이걸 참 잘 해서라는 거 같다
그리고 JVM의 지원도 끝내주고..
그건 그렇구요
그다음은 지역성에 대해 이야기한다.
locality
지역성의 법칙:
프로그램은 최근에 사용한 인스트럭션이나 데이터들의 주소와
가깝거나 동일한 곳의 데이터를 많이 사용하는 경향이 있다.
가까운 곳의 데이터를 쓰면 spatial locality
동일한 곳의 데이터를 (짧은 기간 동안 여러번) 쓰면 temporal locality
이걸 지켜야 빠르다. 왜? 캐시를 쓰니까
멍청한 예제도 하나 소개해 준다

이런 짓은 아무도 안 하지만 어쨌든 이러면 안 되요
근데 전에 이런 거 일일이 생각하면 머머리된다는 개드립을 친 적이 있는데...
배워보니 locality 정도는 생각해야 되겠다. 너무 중요하다. 머머리가 되는 걸 강요받고 있다!
The Memory Hierarchy
솔직히 빠른 놈이 용량도 크고 값까지 싸다면 그놈으로 메모리를 도배하면 되겠으나
응 아니야~
그러한 현실의 제약을 해결하기 위해 cache는 hierarchy 구조로 구현된다.
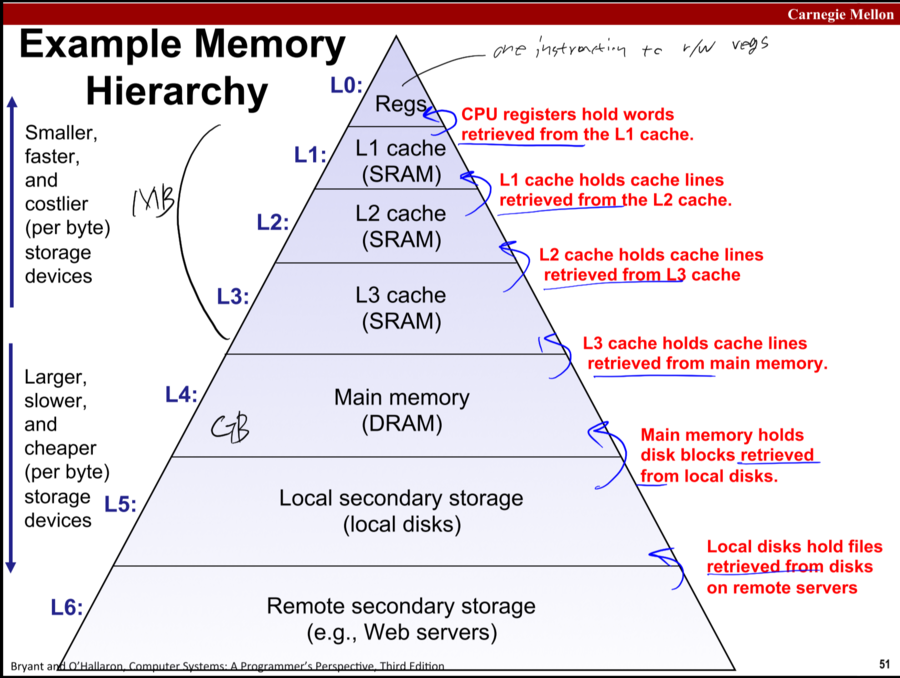
아래쪽의 큰 용량을 가지며 느리지만 값싼 저장장치에서
위쪽의 비싸고 용량은 작지만 빠른 저장장치로
지금 쓰려는 데이터들을 옮긴다.
(지역성의 법칙에 의해 지금 쓰려는 데이터는 어차피 하부에 저장된 데이터의 일부이므로 가능)
이것이 cache이다.
그리고 k레벨의 저장장치는 k+1레벨 저장장치의 cache 역할을 한다.
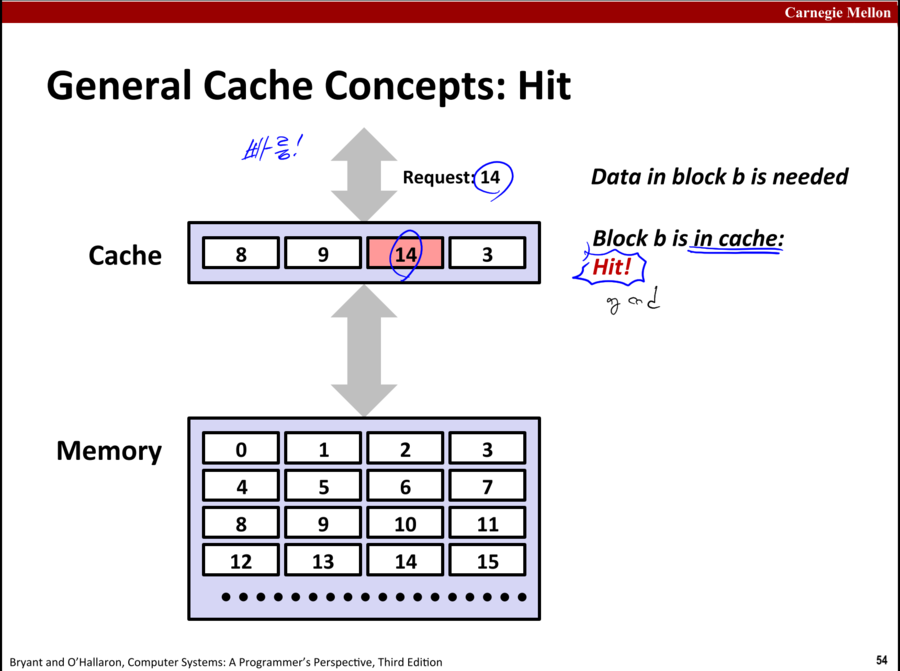
cache hit는 CPU가 지금 쓰려는 데이터가 cache(즉 상위 저장장치)에 존재 하는 경우를 의미한다
캐시 히트는 좋은 것이다!
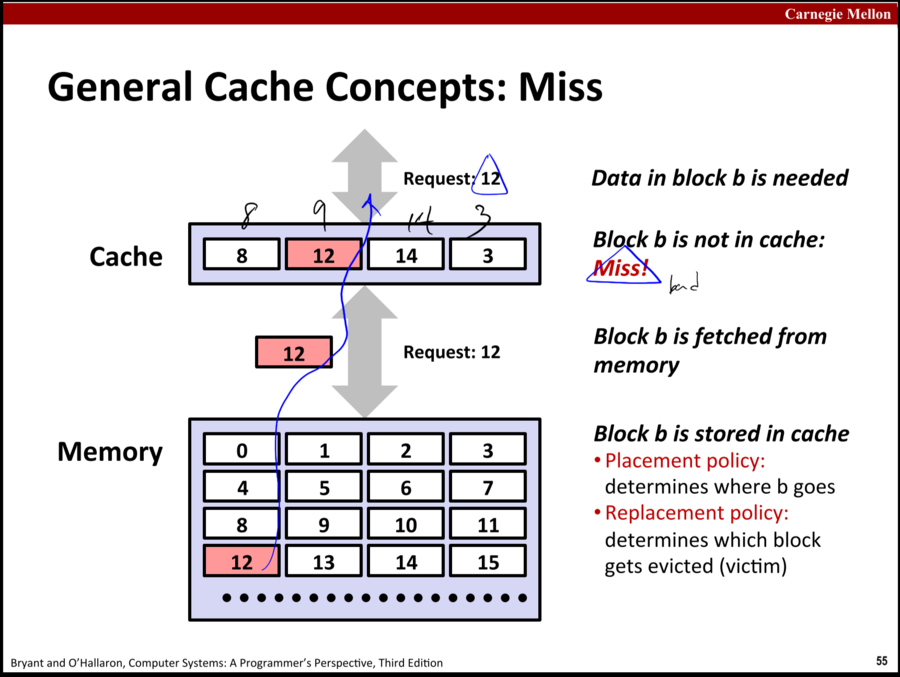
cache miss는 CPU가 지금 쓰려는 데이터가 cache(즉 상위 저장장치)에 존재하지 않는 경우를 의미한다
당연히 더 하위의 저장장치에까지 데이터를 요청해야 되고 시간이 오래 걸린다.
이 현상은 해로운 현상이다!
그러하다.
실제 응용
근데 우리 프로그래머들에게 결국 중요한 것은 무엇인가?

그렇다. 후로훼셔널 후로그래머라면
코드를 딲! 보는 순간 지역성이 있는지 없는지 파악할 수 있어야 한다
아무리 메모리를 서열로 잘 구성해놔도 프로그램이 안 쓰면 말짱 황이다
이 맛에 제가 CS:APP 빱니다... 프로그래머한테 진정으로 중요한 걸 말해준다 이거지요...
끗