블로그 프로젝트 피처 - prev / next
(블로그 만들면서 자료구조 지식 응용한 썰)

내 블로그에는 Series라는 피처가 있는데, 포스트 마크다운 파일의 frontmatter에 미리 정의한 형식의 태그를 달면, 그 태그가 달린 포스트들은 시리즈가 되서 여기서 볼 수 있음. 태그는 대충 #시리즈이름/1 #시리즈이름/2 ... 이런 식임. 그러면 시리즈는 "시리즈이름"이 되고, 포스트들은 저 숫자 순서대로 정렬됨.

시리즈 태그가 부여된 포스트 페이지에는 위 글처럼 이전글/다음글로 시리즈를 편하게 볼 수 있는 링크를 달아 줌.
그 외에도 모든 포스트에는 파일 생성 시간에 따라 부여되는 유일한 id가 있고, 이 id에 따라 이전 글 / 다음 글 링크도 표시하는 피처도 있음. (위 짤에서 kurXXXXX.. 로 표시된 게 id)
이 피처들을 어떻게 만들 수 있을까?
띵킹
(look.post/html post-entity prev-post-id next-post-id prev-chapter-id next-chapter-id)
가장 간단하고 뻔한 방법은 post 페이지를 렌더링하는 함수 html에 저 4가지의 페이지의 id를 넣는 거임.
그러면 id만 가지고 링크를 만들 수 있음(웹 api를 그렇게 구성해 둠)
하지만 이 방법을 써도 결국 저 4가지 페이지 id를 어떻게든 찾아야 하니까 렌더링 함수 밖에서 처리가 필요함. 그런데 이런 id를 찾는 것도 렌더링 로직의 일부라고 생각했고, 4개나 처넣어야 하는 인터페이스가 그냥 구리다고 생각했음. 확장성도 떨어지고:
- 만약 시리즈 전/후, id 전/후 외에 또 다른 전/후 링크들을 넣고 싶어지면?
- 만약 렌더링에서 전/후 페이지의 id보다 더 많은 정보가 필요하다면?
(look.post/html post-entity posts)
그냥 post-entity와 그 외 모든 포스트 엔티티들을 저장해둔 자료구조 posts를 받는 함수를 쓰는 게 맞다고 생각함.
그렇다면 posts는 어떤 자료구조여야 할까?
- id로 원하는 포스트를 가져올 수 있고
- 특정 id의 전prev 후next 포스트를 가져올 수 있어야 함.
좀 생각해보다가 이건 딱 sorted-set이 맞다고 생각했음. Clojure에서 집합을 구현하는 콜렉션 중 하나인데, sorted-set-by 함수를 쓰면 원하는 기준으로 정렬된 집합을 만들 수 있음.
- hash-map을 쓰는 방법이 있는데, 이러면 굳이 콜렉션을 두 개(key의 리스트, 해시맵) 다루는 게 불편함. post 엔티티를 바로 가져오면 되니 그냥 set을 쓰는 게 맞다고 생각함
- 근로저에는 hash 함수를 쓰는 set이라는 게 있음. 보통 이걸 많이 쓰고, 자주 쓰라고 리터럴 문법도 있음:
#{1 2 3 4}근데 왜 이걸 안 쓸까? 이번에는 두번째 요구사항2. 특정 id 전 후 포스트를 가지고 와야 하기 때문임.
여기까지 생각했을 때, 멀쩡한 언어라면 정렬된 자료구조에서 특정 원소를 logN으로 가져오는 함수가 표준 라이브러리에 있을 거라 생각했음. (이 때까지만 해도 그 함수의 이름을 몰랐음)
아니나 다를까 Clojure에도 그런 함수가 있었음: subseq, rsubseq. 여기서는 원소 하나가 아니고 콜렉션의 일부를 시퀀스로 반환하더라. 이 함수들을 설명하자면
(subseq (sorted-set 1 2 3 4 5) > 2) ;=> (3 4 5)
(subseq (sorted-set 1 2 3 4 5) < 3) ;=> (1 2)
(rsubseq (sorted-set 1 2 3 4 5) > 2) ;=> (5 4 3)
(rsubseq (sorted-set 1 2 3 4 5) < 3) ;=> (2 1)
대충 뭔지 알겠지? 중요한 건 저걸 logN으로 한다는 거임. 바이너리 서치를 쓸테니까.
구현
암튼 그래서 나는 다음 코드를 짰고.
(defn prev-next
"Assume sorted-post-set is sorted in descending order.
So, get n,p from (next post prev). ex: kur500 kur404 kur000"
[post sorted-post-set]
(let [prev (first (subseq sorted-post-set > post))
next (first (rsubseq sorted-post-set < post))]
[(when-not (policy/admin-post? prev) prev)
(when-not (policy/admin-post? next) next)]))
렌더링 함수에서 써먹음
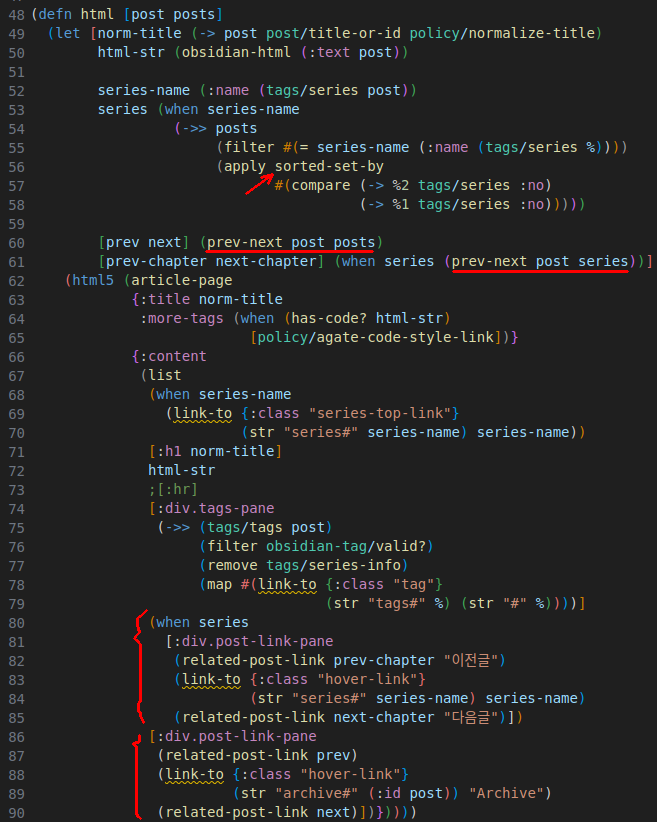
어차피 근로저 읽을 줄 아는 사람 별로 없을테니까, 그냥 느낌으로만 보셈.
53-58 라인에서, posts 중 시리즈 태그가 있는 포스트를 필터링한 다음, 시리즈의 :no 기준으로 정렬된 sorted-set을 만듦.
그걸 61 라인에서 아까 정의한 prev-next 함수를 써서 시리즈의 전/후 포스트 엔티티를 각각 prev-chapter, next-chapter라는 로컬변수로 바인딩함.
그리고 60 라인, posts는 애초에 id로 정렬된 sorted-set이니까, 그냥 prev-next를 쓰면 id에 따른 전/후 포스트를 만들 수 있음
이제 그것들로 페이지(html)를 렌더링함. 86-90라인에서, id 전/후 링크에 대한 pane을 렌더링함. 그리고 80-85 라인에서, 시리즈가 있는 경우(when series ...) 시리즈 link가 있는 pane을 렌더링함(시리즈가 없는 포스트도 있으니까).
맺음말
사실 블로그 포스트는 1000개도 넘기기 힘드니까 이런 짓 안하고 대충 떡쳐도 성능으로는 큰 문제 없음. 실제로 시리즈를 묶어내서 계산을 한번만 한다거나 기타 등등 똥꼬쇼를 더 할 수도 있겠지만 귀찮아.. 그냥 이렇게 할래...
꼭 필요한 성능딸은 아니지만 그래도 응용 프로그래밍에서 이렇게 대놓고 자료구조 지식을 써 본 게 오랜만이라 썰을 풀어 봄.
그리고 subseq 같은 거 있겠지? 했더니 정말 있어서 기분 좋았음. 역시 근로저야..
우리 근로저 하자 나부터 시작했어